
Deploying VLM on Jetson
(Complete Edge AI Guide)
Introduction
Computer vision is evolving rapidly. For years, most systems relied on discriminative AI, which focuses on tasks such as object detection or segmentation. While effective, these systems remain limited because they only recognize what they were trained to detect.
However, Vision Language Models (VLMs) change this completely. Instead of only detecting objects, they understand scenes, relationships, and intent using natural language. Until recently, deploying VLMs required powerful cloud GPUs.
Fortunately, lightweight models like SmolVLM now make it possible to deploy Vision Language Models on NVIDIA Jetson devices. As a result, real-time visual reasoning is finally moving to the edge.
Why Vision Language Models Belong at the Edge?
Traditionally, visual understanding required sending video streams to the cloud. However, this approach introduces several critical problems.
First, latency becomes unavoidable, which is unacceptable for safety or robotics systems.
Second, privacy risks increase when sensitive video data leaves the site.
Finally, bandwidth costs rise rapidly when streaming high-resolution video continuously.
By deploying Vision Language Models on NVIDIA Jetson, intelligence moves closer to the camera. Consequently, the system no longer just records video — it actively reasons locally.
SmolVLM: A Lightweight VLM for NVIDIA Jetson
SmolVLM is a compact multimodal model designed for efficiency. Unlike large cloud-based VLMs, it fits well within the memory and power constraints of Jetson devices.
Why does SmolVLM work on Jetson?
- Low memory footprint, ideal for Orin Nano and Orin NX
- Unified memory architecture, reducing data transfer overhead
- Quantization support, enabling FP16 and INT8 acceleration
- Tensor Core optimization, leveraging NVIDIA Ampere GPUs
As a result, SmolVLM delivers meaningful visual reasoning without requiring enterprise hardware.
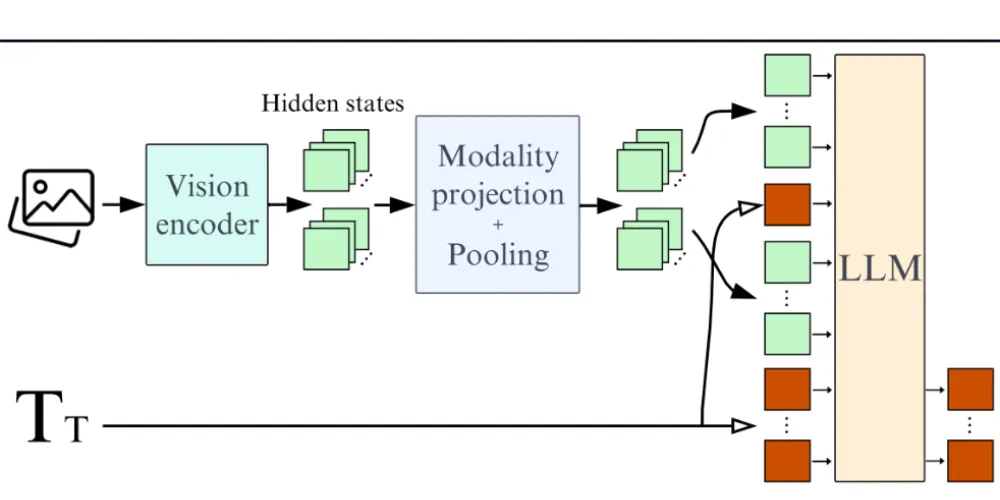
Understanding the VLM Inference Pipeline
To understand its value, it helps to compare VLMs with traditional vision models.
VLM Inference Flow
- Vision Encoder converts images into visual tokens
- Projection Layer aligns vision tokens with language space
- Language Model generates contextual text responses
Unlike object detectors that output coordinates, VLMs output explanations. Therefore, they don’t just detect a helmet — they explain why its absence is risky.
Event-Driven Video Reasoning on Jetson
Running VLMs on every video frame is unnecessary. Instead, edge systems use an event-driven approach.
How It Works
- A lightweight detector monitors video at high FPS
- An event triggers frame sampling
- SmolVLM analyzes selected frames for reasoning
This hybrid approach ensures real-time responsiveness while preserving compute efficiency.

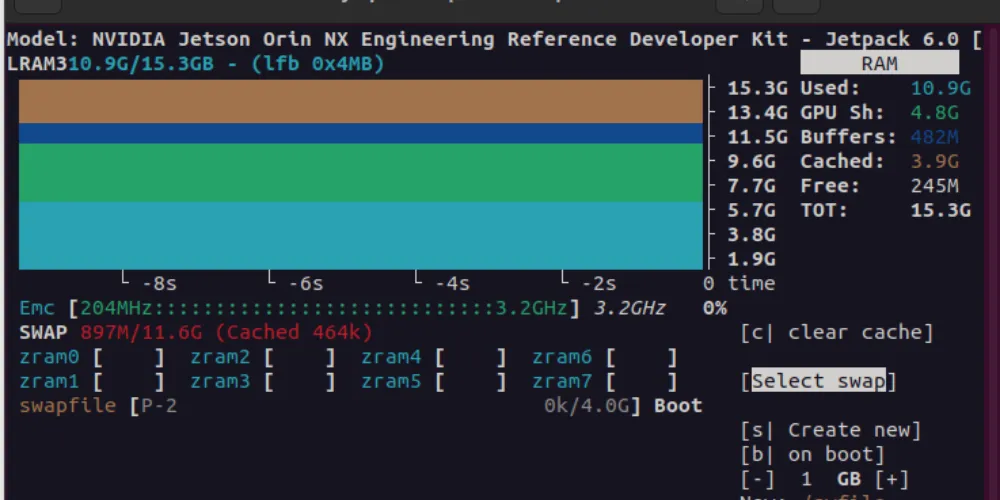
Real-World Reasoning Performance
When tested on the NVIDIA Jetson Orin NX, SmolVLM demonstrated strong reasoning ability during visual question answering tasks.
Observed Performance
- GPU utilization peaks during inference
- CPU usage remains low, preserving system stability
- Memory stays within safe operational limits
Consequently, the system runs reliably without stressing hardware resources.

Real-World Applications of VLMs on Jetson
Industrial Safety
- Detects PPE presence and contextual compliance
- Explains unsafe behavior in plain language
Smart Surveillance
- Goes beyond motion alerts
- Explains intent and anomalies clearly
Robotics & HMI
- Understands natural language instructions
- Connects human intent to robot navigation
Limitations to Consider
Despite its strengths, SmolVLM is not perfect.
- Not designed for high-FPS action recognition
- Occasional hallucinations if prompts are poorly designed
- Reduced accuracy for very small visual details
Nevertheless, when used correctly, its benefits far outweigh its limitations.
Conclusion: The Future Is Edge-Based
Deploying Vision Language Models on NVIDIA Jetson represents a major shift in AI deployment. Instead of relying on cloud inference, systems can now see, understand, and explain locally.
Ultimately, SmolVLM proves that powerful visual reasoning no longer requires massive infrastructure. Instead, it enables scalable, private, and cost-effective edge intelligence.
Partner With Us
At AI India Innovations, we specialize in deploying edge AI solutions using NVIDIA Jetson, Vision Language Models, and multimodal pipelines.
Whether you’re building robotics systems, smart cameras, or industrial safety platforms, we help you move from prototype to production — faster and smarter.
👉 You can explore more of our work in the Blogs section on our website.
Happy reading!
